
La prise en charge de la déficience auditive représente un enjeu majeur de santé publique. La mise en place du 100 % Santé pour les audioprothésistes le confirme, mais cette réforme implique une démarche de validation des résultats1. Les professionnels doivent être capables de démontrer à la fois aux utilisateurs et aux pouvoirs publics que l’appareillage et le service associé ont un impact positif sur la qualité de vie des patients. En octobre 2018, la Commission nationale d’évaluation des dispositifs médicaux et des technologies de santé (CNEDiMTS) avait dressé la liste des amendements à l’avis de projet de la nouvelle nomenclature publié au Journal officiel. Elle proposait que la prestation initiale comprenne :
- l’écoute des demandes de la personne du patient,
- l’évaluation de sa gêne,
- de son seuil d’inconfort,
- de sa motivation par un questionnaire validé type COSI2 (Client Oriented Scale of Improvement),
- de ses besoins spécifiques,
- de son contexte médico-social au cours d’une anamnèse détaillée.
Une démarche holistique
La création de notre outil, dédié au repérage des troubles auditifs et à l’évaluation des patients appareillés ou implantés, repose sur ce constat et propose une démarche holistique agissant sur 7 points :
- Amélioration du repérage auditif : favoriser la sensibilisation du patient et rendre le repérage plus impliquant.
- Aide au diagnostic : développer une dimension qualitative et individualisée en déterminant le niveau de gêne auditive « in situ ».
- Optimisation du choix prothétique : se baser sur les environnements sonores du patient pour choisir le type de technologie requise.
- Optimisation des réglages : analyser les besoins d’écoute individuels pour ajuster les réglages.
- Evaluation écologique du bénéfice : tester l’impact des modifications des réglages au regard des différentes situations sonores.
- Entraînement auditivo-cognitif : générer un entraînement ciblé pour améliorer les capacités.
- Outil d’alerte et de suivi : obtenir un score de performance référentiel et être alerté en cas d’évolution négative, afin de réagir au plus vite.
Pour améliorer les algorithmes de traitement du signal dans les aides auditives, il est nécessaire de considérer les conditions écologiques3. Mais pour réussir, il faut préalablement caractériser les conditions sonores des activités de communication.

Gatehouse, Elberling et Naylor4 furent les premiers à utiliser l’expression auditory ecology pour désigner la relation entre les environnements acoustiques du quotidien et les exigences perceptuelles des sujets dans ces situations. Dès lors, bon nombre d’études se sont focalisées sur l’analyse des environnements sonores. La revue de littérature de Wolters et al.5 en recense 41 : dans le cadre de notre projet, nous en avons retenu six. La plupart, collectant des enregistrements sonores couplées à l’Ecological Momentary Assessment6.
- Wagener et al.7 : 20 sujets équipés d’aides auditives (moy. = 51,4 ans) et issus de catégories socio-professionnelles différentes, ont enregistré à leur guise, différentes situations sonores de leur vie courante par tranche de 5 à 10 minutes, pendant 3 à 4 jours. 349 situations furent recueillies et classées par fréquence d’occurrence.
- Eckardt et al.8 : L’analyse s’est portée sur le temps passé dans les différentes situations sonores. 10 personnes normo-entendantes (5 sujets jeunes moy = 26 ans et 5 sujets plus âgés moy. = 65 ans) et 10 personnes malentendantes (moy. = 67 ans) étaient équipées de dosimètres et devaient également renseigner de manière digitale les situations dans lesquelles elles se trouvaient. 874 données ont été enregistrées.
- Jensen & Nielsen9 : L’approche est sensiblement la même chez 18 sujets appareillés : l’intérêt majeur est la pertinence du questionnaire utilisé pour l’évaluation subjective des difficultés d’écoute dans chacun des 7 environnements préétablis par les auteurs.
- Wu & Bentler10 : 27 sujets âgés de 20 et 90 ans équipés de dosimètres devaient décrire in situ les caractéristiques de leurs environnements sonores. L’originalité se trouvait dans la catégorisation de 30 environnements, répertoriés à partir de 6 activités réparties en 5 catégories.
- Walden et al.11 : L’approche est très différente. Les situations sonores prototypiques ont été définies à partir de l’analyse de 5 variables acoustiques. 1599 échantillons sonores ont été recueillis auprès de 17 sujets appareillés (moy. = 70,8 ans), aboutissant à la création de 24 archétypes de situations sonores.
- Wolters et al.3 : les données de dizaines d’études ont été synthétisées pour définir les « Common Sound Scenarios » constituant une catégorisation des environnements sonores quotidiens.
Création des environnements sonores
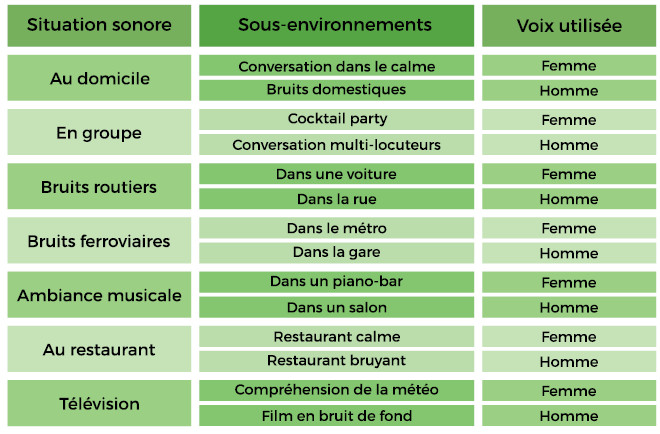
Nous avons opté pour un « profilage » ciblant 7 situations sonores représentant plus de 85 % de nos situations conversationnelles (voir tableau 1). Chaque situation sonore ciblée comprend 2 sous-environnements qui seront potentiellement testés avec une voix de femme puis une voix d’homme.
Pour chaque environnement, trois informations sont recueillies grâce à des échelles de Likert :
- La fréquence d’occurrence
- La gêne auditive
- L’envie d’améliorer sa compréhension
À l’issue de ce profilage auditif, un algorithme détermine une hiérarchisation des environnements sonores et entraîne une évaluation auditive personnalisée.
Trois niveaux de RSB évalués
Après une calibration du niveau de sortie (bruit blanc à 65 dB), le sujet entend une phrase constituée de 3 mots cibles et restitue ce qu’il a compris grâce un QCM à 3 choix par mot cible.
Chaque sous-environnement est testé à 3 niveaux de rapport signal/bruit par une procédure adaptative à la performance.
L’échelle de performance est déterminée à partir de 2 types de données :
- La valeur de performance maximale, après normalisation de chaque phrase auprès de normo-entendants.
- Le niveau moyen de RSB au regard de la littérature12,13.
À l’issue du test, le patient obtient une note pour chaque environnement testé. Elle est basée sur le RSB du dernier niveau atteint et sur le nombre de mots cibles identifiés à ce niveau.

2 520 éléments sonores
Sur le plan linguistique, chaque sous-environnement sonore bénéficie de son propre modèle de phrase qui peut donc différer sur le plan morphosyntaxique entre 2 sous-environnements, mais va rester identique dans un sous-environnement donné.
Les phrases de chaque sous-environnement présentent le même nombre de syllabes, la variation résidant dans le remplacement des mots-cibles par des mots équivalents et phonétiquement proches ; les phrases devant rester correctes sur le plan syntaxico-sémantique, tout en restant faiblement prédictives sur le plan lexical.
L’ensemble des phrases a été généré en voix de synthèse. Aléatoirement, pour chaque sous-environnement sonore, 30 phrases ont été sélectionnées. 13 bruits de fond (hors situation dans le calme) ont été enregistrés in situ à l’aide d’un micro 360 ° Zoom H3-Vr. Pour chacun, une plage représentative de 10 secondes a été sélectionnée.
L’ensemble « phrase + bruit de fond » a été mixé et time-locké. Chaque phrase a été générée à 6 niveaux de RSB différents. Le tout constituant une base de données de 2 520 éléments.
Lauréat Silver Surfer
Différents prototypes ont été créés au sein d’une équipe pluridisciplinaire (ORL, orthophonistes, audioprothésistes). Ils ont été testés auprès de patients normo-entendants, malentendants non-appareillés, appareillés et auprès de sujets implantés cochléaires) pour aboutir à une version bêta. Celle-ci a servi de preuve de concept dans le cadre du concours Silver Surfer organisé par Eurasanté et s’est vue désignée « Lauréats 2019 ».
Dans ce cadre, une agence indépendante en ergonomie, UseConcept, a testé la plate-forme grâce à des outils standardisés (échelles SUS et EAQ) auprès de 2 types de population :
- Une équipe d’audioprothésistes auprès desquels l’outil a obtenu une note de 93/100 ce qui confirme sa facilité d’utilisation et son intérêt dans la prise en charge audioprothétique.
- Un échantillonnage « Grand public » (critères propres à UseConcept) qui a montré que :
- 97 % des sujets indiquent que l’outil permet de caractériser efficacement la gêne auditive ;
- 93 % confirment que les situations modélisées sont représentatives du quotidien ;
- 90 % admettent que le score obtenu reflète leur niveau de performance auditive.
En routine à Lille
L’outil est aujourd’hui utilisé au quotidien dans les Laboratoires d’audiologie Renard et au sein du service d’otologie et d’oto-Neurologie du Pr Christophe Vincent au CHRU de Lille. Il permet de s’inscrire pleinement dans les recommandations de la CNEDiMTS, en recueillant des informations sur la gêne auditive et les besoins d’écoute quotidiens des patients et en proposant des réglages qui s’y conforment. Cela contribue à l’amélioration du bénéfice prothétique et de la qualité de vie des patients. Le développement actuel de la plate-forme porte sur la mise en place d’un programme d'entraînement auditif associé et l’implémentation d’un module de suivi et d’alerte.

